

Each year, more data are produced than the year before. In 2020, over 59 zettabytes (1 ZB = a trillion gigabytes) has been “created, captured, copied, and consumed in the world” . And this trend is not about to stop. With the democratisation of Internet of Things (IoT) devices, that are expected to outnumber the number of “traditional” connected devices (smartphones, tablets and computers), and the adoption of 5G network, the amount of data produced and consumed will skyrocket. We estimate that more data will be created over the next three years than the data created over the past 30.
Hence, the digital transformation of society is coming at a rapid rate, and with it questions on the ethical use of information. Questions over the access of information, the ownership of data, the transparency in its uses and more are at the core of any digital solutions. In the EU, answering those questions has been facilitated with the implementation of the General Data Protection Regulation (GDPR). GDPR ensures data protection and preserves individuals privacy. Under such regulation, processing of personal data is prohibited without an unambiguous consent from the owner unless it is expressly allowed by law.
Such regulation is certainly a constraint for us researchers and forces us to be imaginative in our methods. In this article, we will present the concept of synthetic data, our solution when facing sensitive data.
The COVID crisis and synthetic population
The COVID crisis presents administrators, politicians, enforcers and citizens difficult issues and dilemmas. We already know a lot more about the virus than we did at the beginning of the crisis, but much remains unclear. For example, there are still a lot of uncertainties on how the virus spreads among the population and the contact tracing. What certainly plays a role in this lack of clarity is that much of the available information cannot be used and/or accessed directly. We have a great amount of information about individuals, their households, health and more that we could use to better understand and/or prevent the virus propagation. However, those very sensitive information cannot be used directly in our research. The trade-off between “public health” on the one hand and “privacy” is a difficult challenge.
Enter synthetic data.
Data synthesis is the process of creating a dataset from a source dataset while ensuring that important statistical properties are maintained. In other words, the synthetic dataset, although different from the original data, is still statistically relevant for modelling and analysis purposes. The advantage of the approach is that we now have a dataset that respects the privacy and security of its source and that can be directly used for subsequent applications.
In our current research project on Mobility patterns in the Context of a Pandemic, we are leveraging the power of data synthesis for the creation of a Synthetic Population. Through our collaboration with the Centraal Bureau voor de Statistiek (CBS) and the Vrije Universiteit Amsterdam, we are aiming at generating a synthetic dataset of the population using microdata about individuals.
The Power of Artificial Intelligence
When it comes to data synthetic, Artificial Intelligence can certainly help. If some statistical tools exist and have already implemented such as the iterative proportional fitting (IPF) , AI algorithm have proven to be efficient over the task. More specifically, 2 deep learning models have been favored in the literature, Variational Autoencoder (VAEs) and Generative Adversarial Networks (GANs).
VAEs
VAEs are unsupervised generative models that are trained to encode data into a lower-dimensional space (also called latent space) and decode it back to its original space while trying to minimize the resulting reconstruction error.
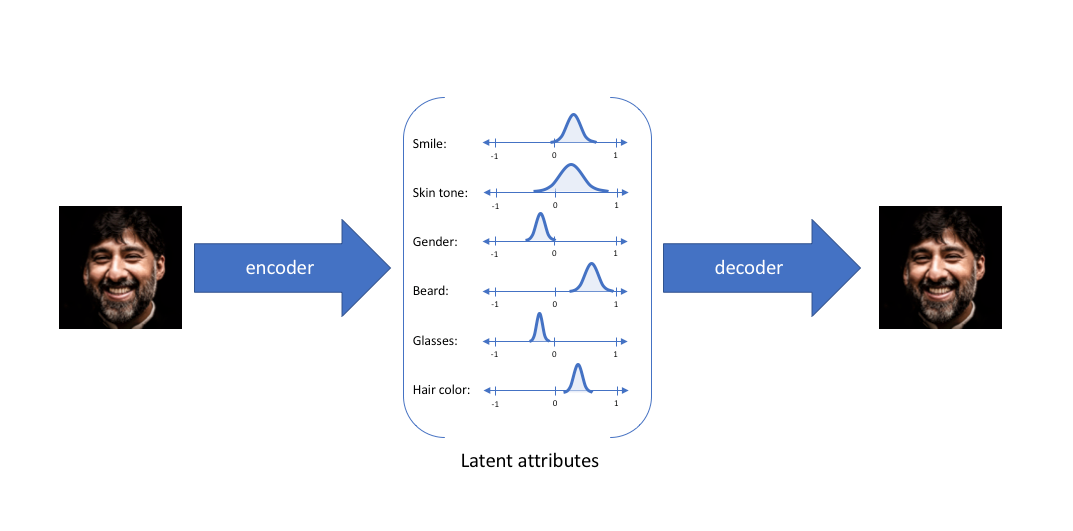
The latent space and decoder can therefore be used for generating synthetic data while minimizing divergence between probability distributions. The outcome would then be a reconstructed dataset that remains statistically relevant without including any original information.
GANs
GAN are equally widespread deep learning algorithms for synthetic data generation. They have been heavily used for imagery, music, speech, text generation. For instance, NVidia research has used a GAN algorithm for style-based image generation that “captures” images’ features to blend them in the latent space and create a newly combined image.

GANs work by opposing two neural networks, the generator model and the discriminator model. The generator aims at generating new data from the input data while the discriminator aims at classifying those new instances as either real or fake. The two models are trained together in a zero-sum game until the discriminator is fooled and the generator generates “realistic” instances.
Note: For more example of GANs implementation, I recommend exploring the playful https://thispersondoesnotexist.com/ and its spin-offs https://thisxdoesnotexist.com/.
If you are curious to know more about those two models, I recommend the following introduction videos by Arxiv:
VAE: https://youtu.be/9zKuYvjFFS8
GAN: https://youtu.be/dCKbRCUyop8
Thankfully for us, those models and their derivatives have already been studied extensively and many robust tools are now available. There exist multiple private companies that offer to generate synthetic datasets using AI, or more noticeably, the open source project, Synthetic Data Vault, developed by the MIT that offers a Synthetic Data Generation ecosystem for python.
Conclusion
Synthetic data are already present in the literature and many efforts have been done by renowned companies and research institutions to perfect the method. The MIT as mentioned above but also Amazon, using synthetic data to train Alexa’s language system, Google, to train their autonomous vehicles, American Express to improve fraud detection etc. The application are numerous and some believe that the technology will become a pillar of the digital economy in a world where privacy is key.
For us researchers, the technology is the promise to have sufficient privacy-preserving datasets to perform our studies and modelling activities.